This notebook introduces the python library delab_trees and showcases on some examples how it can be useful in dealing with social media data.
Target Audience
This library is intended for advanced CSS researchers that have a solid background in network computing and python
Motivated intermediate learners may use some of the toolings as a blackbox to arrive at the conversation pathways later used in their research
Prerequisites
Before you begin, you need to know the following technologies.
python
networkX
pandas
Set-up
In order to run this tutorial, you need at least Python >= 3.9
the library will install all its dependencies, just run
pip install delab_trees
Social Science Usecases
This learning resource is useful if you have encountered one of these three use cases:
deleted posts in your social media data
interest in author interactions on social media
huge numbers of conversation trees (scalability)
discussion mining (finding actual argumentation sequences in social media)
Sample Input and Output Data
Example data for Reddit and Twitter are available here https://github.com/juliandehne/delab-trees/raw/main/delab_trees/data/dataset_[reddit|twitter]_no_text.pkl. The data is structure only. Ids, text, links, or other information that would break confidentiality of the academic access have been omitted.
The trees are loaded from tables like this:
tree_id
post_id
parent_id
author_id
text
created_at
0
1
1
nan
james
I am James
2017-01-01 01:00:00
1
1
2
1
mark
I am Mark
2017-01-01 02:00:00
2
1
3
2
steven
I am Steven
2017-01-01 03:00:00
3
1
4
1
john
I am John
2017-01-01 04:00:00
4
2
1
nan
james
I am James
2017-01-01 01:00:00
5
2
2
1
mark
I am Mark
2017-01-01 02:00:00
6
2
3
2
steven
I am Steven
2017-01-01 03:00:00
7
2
4
3
john
I am John
2017-01-01 04:00:00
This dataset contains two conversational trees with four posts each.
Currently, you need to import conversational tables as a pandas dataframe like this:
import osimport sysimport warningsimport numpy as np # Example module that might trigger the warning# assert that you have the correct environmentprint(f"Active conda environment: {os.getenv('CONDA_DEFAULT_ENV')}")# assert that you have the correct python version (3.9)print(f"Python version: {sys.version}")# Suppress the specific VisibleDeprecationWarningwarnings.filterwarnings("ignore", category=np.VisibleDeprecationWarning)# the interesting codefrom delab_trees import TreeManagerimport pandas as pdd = {'tree_id': [1] *4,'post_id': [1, 2, 3, 4],'parent_id': [None, 1, 2, 1],'author_id': ["james", "mark", "steven", "john"],'text': ["I am James", "I am Mark", " I am Steven", "I am John"],"created_at": [pd.Timestamp('2017-01-01T01'), pd.Timestamp('2017-01-01T02'), pd.Timestamp('2017-01-01T03'), pd.Timestamp('2017-01-01T04')]}df = pd.DataFrame(data=d)manager = TreeManager(df) # creates one treetest_tree = manager.random()test_tree
Active conda environment: notebook
Python version: 3.9.19 | packaged by conda-forge | (main, Mar 20 2024, 12:50:21)
[GCC 12.3.0]
loading data into manager and converting table into trees...
2026-04-01 07:19:56.490606: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2026-04-01 07:20:05.155401: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2026-04-01 07:20:05.156047: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2026-04-01 07:20:15.567080: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
0%| | 0/1 [00:00<?, ?it/s]100%|██████████| 1/1 [00:00<00:00, 143.01it/s]
<delab_trees.delab_tree.DelabTree at 0x7fe7ef48ddf0>
Note that the tree structure is based on the parent_id matching another rows post_id.
You can now analyze the reply trees basic metrics:
from delab_trees.test_data_manager import get_test_treefrom delab_trees.delab_tree import DelabTreeimport warningsimport numpy as np# Suppress only VisibleDeprecationWarningwarnings.filterwarnings("ignore", category=np.VisibleDeprecationWarning)test_tree : DelabTree = get_test_tree()assert test_tree.average_branching_factor() >0print("number of posts in the conversation: ", test_tree.total_number_of_posts())
loading data into manager and converting table into trees...
number of posts in the conversation: 4
'The dataset contains 6 conversations and 24 posts in total.\nThe average depth of the longest flow per conversation is (2, 4, 3.1666666666666665).\nThe conversations contain 6 authors and the min and max number of authors per conversation is min:2, max: 4, avg: 3.3333333333333335.\nThe average length of the posts is 10.0 characters.\n'
In order to check if all the conversations are valid trees which in social media data, they often are not, simply call:
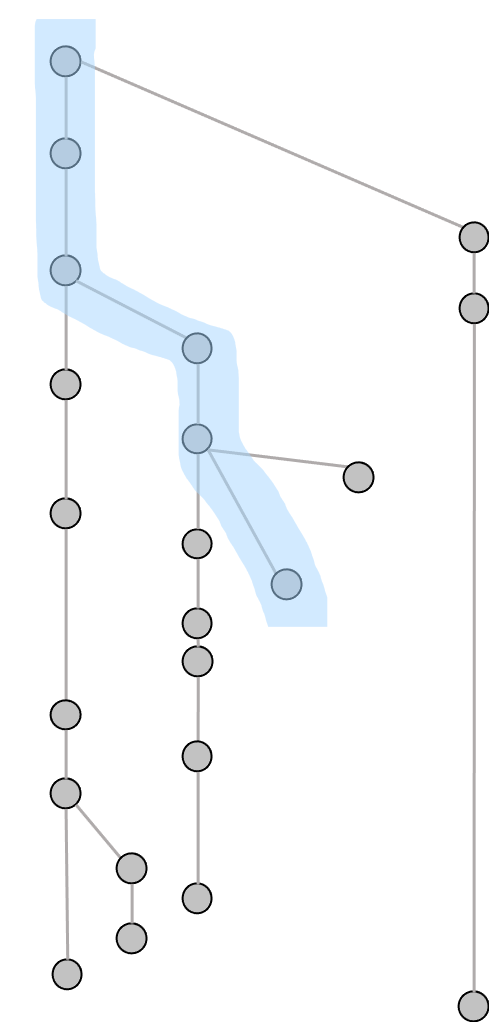
As an analogy with offline-conversations, we are interested in longer reply-chains as depicted in Figure 1. Here, the nodes are the posts, and the edges read from top to bottom as a post answering another post. The root of the tree is the original post in the online conversation. Every online forum and social media thread can be modeled this way because every post except the root post has a parent, which is the mathematical definition of a recursive tree structure.
The marked path is one of many pathways that can be written down like a transcript from a group discussion. Pathways can be defined as all the paths in a tree that start with the root and end in a leaf (a node without children). This approach serves the function of filtering linear reply-chains in social media (see Wang, Joshi, and Cohen (2008); Nishi et al. (2016)), that can be considered an online equivalent of real-life discussions.
In order to have a larger dataset available we are going to load the provided dataset and run the flow_computation for each tree.
# get the sample treesfrom delab_trees.test_data_manager import get_social_media_treessocial_media_tree_manager = get_social_media_trees()# compute the flowsflow_list = [] # initialize an empty list tree: DelabTree =Nonefor tree_id, tree in social_media_tree_manager.trees.items(): flows = tree.get_conversation_flows(as_list=True) flow_list.append(flows)print(len(flow_list), " were found")# now we are only interested in flows of length 5 or more# Filter to only include lists with length 5 or morefiltered_lists = [lst for lst in flow_list iflen(lst) >=7]print(len(filtered_lists), " lists with length > 7 were found")
loading data into manager and converting table into trees...
6235 were found
5218 lists with length > 7 were found
Use Case 3: compute the centrality of authors in the conversation
test_tree : DelabTree = get_test_tree()metrics = test_tree.get_author_metrics() # returns a map with author ids as keysfor author_id, metrics in metrics.items():print("centrality of author {} is {}".format(author_id, metrics.betweenness_centrality))
loading data into manager and converting table into trees...
centrality of author john is 0.0
centrality of author mark is 0.16666666666666666
centrality of author james is 0.0
centrality of author steven is 0.0
The result shows, that only mark is central in the sense that he is answered to and has answered. In bigger trees, this makes more sense.
Library Documentation
For an overview over the different functions, have a look here
Conclusion
Now you should be able to analyze social media trees effectively. For any questions, write me an email. I am happy to help!
Also I would be happy if someone is interested in doing research and writing a publication with this library!
Exercises or Challenges (Optional)
Learning exercises are forthcoming! But for now you should click on the binderhub link on the top to get a notebook in Jupyterlab, where you can play around with the code.
FAQs (Optional)
This will be filled if more people use the library!
Nishi, R., T. Takaguchi, K. Oka, T. Maehara, M. Toyoda, K.-i. Kawarabayashi, and N. Masuda. 2016. “Reply Trees in Twitter: Data Analysis and Branching Process Models.”Social Network Analysis and Mining 6 (1): 26.
Wang, Y.-C., M. J. M. Joshi, and W. Cohen. 2008. “Recovering Implicit Thread Structure in Newsgroup Style Conversations.”Proceedings of the International AAAI Conference on Web and Social Media 2 (1): 152–60.
@misc{dehne2023,
author = {Dehne, Julian},
title = {Delab-Trees, a Python Library to Analyze Conversation Trees},
date = {2023-09-18},
urldate = {2026-04-01},
url = {https://github.com/juliandehne/delab-trees},
langid = {en}
}
For attribution, please cite this work as:
Dehne, Julian. 2023. “Delab-Trees, a Python Library to Analyze
Conversation Trees.”In F. Kraemer, Y. Peters, A.-K. Stroppe,
J. Daikeler, F. Draxler, F. Kreuter, F. Keusch, T. Knopf, L. Mejia
Lopez, B. Rammstedt, P. Siegers, H. Silber, J. Sun, C. Wagner, K.
Weller, C. Yıldız, S. Jünger, S. Kapidzic, & L. Young (Eds.), KODAQS
Toolbox. https://github.com/juliandehne/delab-trees.
Social Science Usecases
This learning resource is useful if you have encountered one of these three use cases: